Poetry discovery is difficult for the same reasons content discovery has always been difficult:
- categories are boring and don’t work at scale
- search requires knowing what you’re looking for and how to find it
- editorial curation is expensive
We publish a lot of poetry at San Antonio Review, enough that it gets lost in the shuffle. Readers find poems through social media, search engines, the homepage, or browsing by issue. That’s fine for new work, but poetry is evergreen. A poem published three years ago is as relevant as one published last week. We don’t have the editorial resources to constantly resurface older work, and “most popular” lists that go stale have little value for us.
The real problem is that poetry resists simple categorization. A single poem can be melancholic and hopeful and political all at once. Unlike short stories, which are often about something concrete, poems evoke feelings. You can’t neatly sort them into buckets.
So, I built a conversational poetry discovery tool:
https://sanantonioreview.org/poetry/
https://github.com/mistycripps
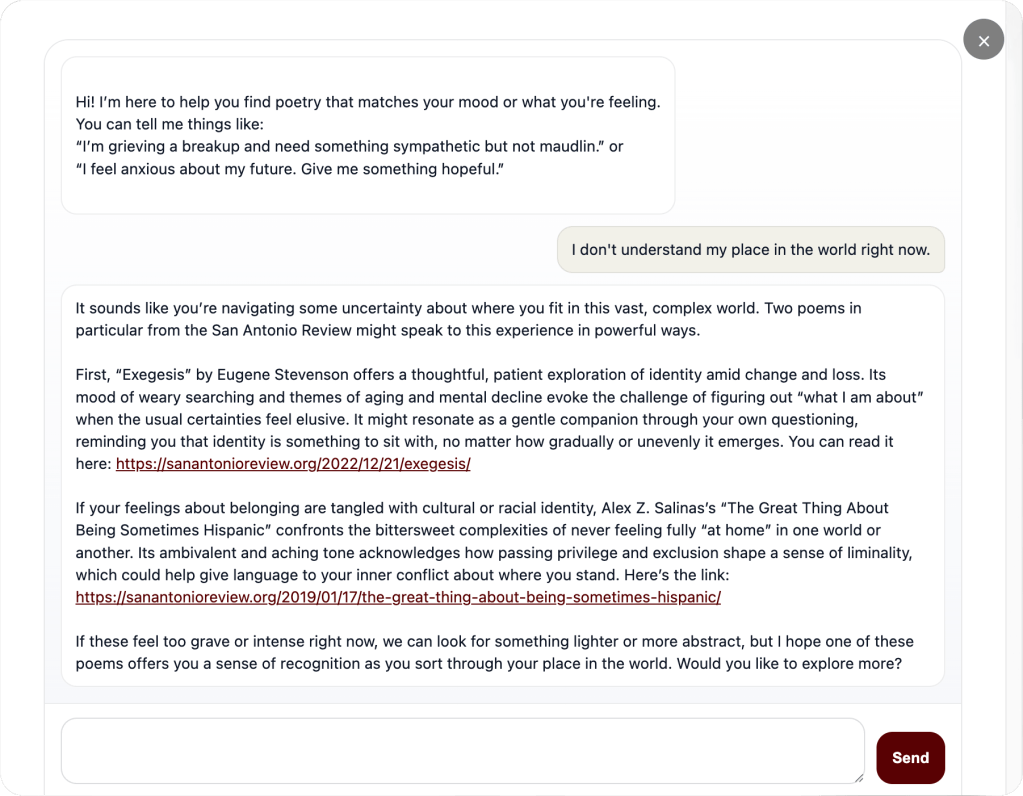
Readers can talk to San Antonio Review about what they want to read. “I want something bittersweet about family.” or “Show me poems about grief that aren’t too sad.” The system uses mood and emotion as its organizing principles rather than traditional categories.
This solves two problems. Readers find emotionally resonant work in the moment, and editors get a new curation tool that doesn’t require constant manual intervention.
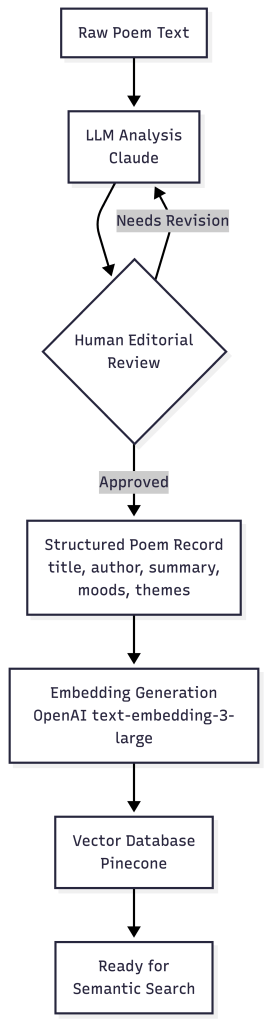
I built this using vector databases and LLMs. To make it work I:
- Analyzed a large subset of our poetry collection.
- Created a controlled vocabulary of moods and themes that reflected the nuance and complexity of the corpus.
- Used an LLM, with editor oversight, to tag poems.
- Created a vector database and implemented RAG + semantic search.
- The LLM handles all the semantic inference. It understands how “melancholic” relates to “wistful” relates to “grief” without me hard-coding those relationships.