
My dog died recently. It was sudden, but not unexpected. He was 15 and suffering from advanced kidney disease.
When I was considering approaches to structuring and classifying data for the Poetry Explorer, I began to think about scenarios like this.
I want to be able to find poetry by saying, “My best fuzzy friend went over the rainbow bridge last week. I’m heartbroken, but also relieved that he is no longer suffering.” Because that is how I felt. Conflicted. Ambivalent. Sad, but also a little relieved that he wasn’t miserable anymore.
This is the kind of complexity I want the system to handle.
Links:
San Antonio Review Poetry Explorer
GitHub
It’s ambitious, and I’m still working on getting that right, but it’s more human and better reflects our complex inner states than saying, “I am sad.”
We have a large body of poetry for a small literary journal. Currently, the inventory stands at approximately 650 published poems and is growing. It’s by far the most popular category, which made it a natural choice for this project. Because the corpus is small , pretrained embeddings were fine without custom training.
With my corpus in hand, I needed a way to classify poems such that emotional nuance was preserved while making them discoverable through semantic search.
This is the first semantic search project I’ve designed, built, and launched myself.
I started by reading academic papers, reviewing GitHub repositories, and examining poetry emotion classification datasets (See the link list at the end of the post). I’m a product designer with a linguistics background, not a machine-learning engineer, so I didn’t fully understand everything I read. I didn’t implement these architectures, but they informed how I thought about representation and retrieval.
I approached the work in three parts:
- Used an LLM to help do an initial analysis of a subset of the corpus.
- Created a classification system of moods and themes based on data from initial analysis.
- Applied the classification system to poems using an LLM with a human as a final reviewer.
I used Claude (Anthropic) for the mood classification because it gave me the best balance of quality results and ease of implementation for a solo designer. The data from Claude was used to create a human-reviewed controlled vocabulary. These are the moods and themes. I used Claude to take an initial pass at assigning them to poems, and a human followed to review its work.
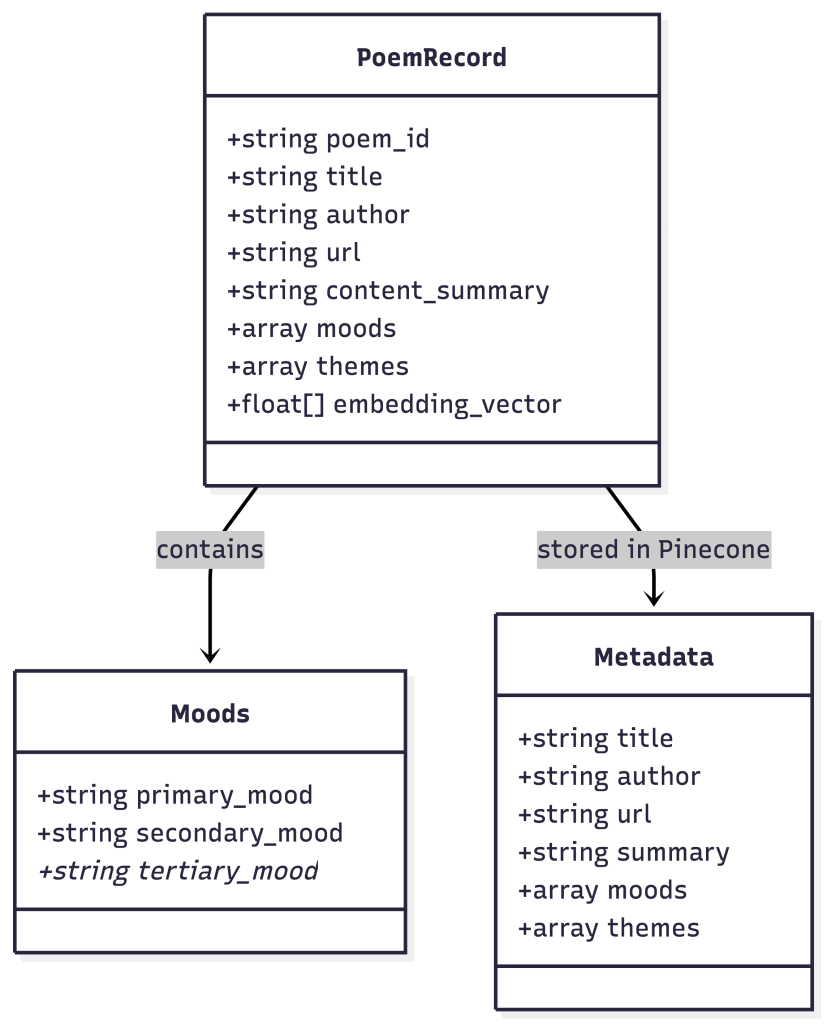
The classification system I created applies a primary mood, a secondary mood, and an optional third mood to each poem. I wanted to avoid excessive granularity, so I chose to use one broad and one more detailed mood for each. I used a broad range of moods because the design goal was for users to find poetry that mapped to richer, more complex internal experiences than “sad” or “happy”. The system continues to evolve, and its vocabulary will expand and contract as it is further tested.
The theme is the central “idea” of each poem. I used the same analysis method to extract themes from that initial set.
The moods and themes are incorporated into the embedding text so that they influence vector similarity. Rather than embedding the full poem text, I generate embeddings from a structured representation of each poem, including its summary, moods, and themes. This means a poem tagged with “sadness,” “ambivalence,” and “pet loss” has all of that baked into its semantic fingerprint.
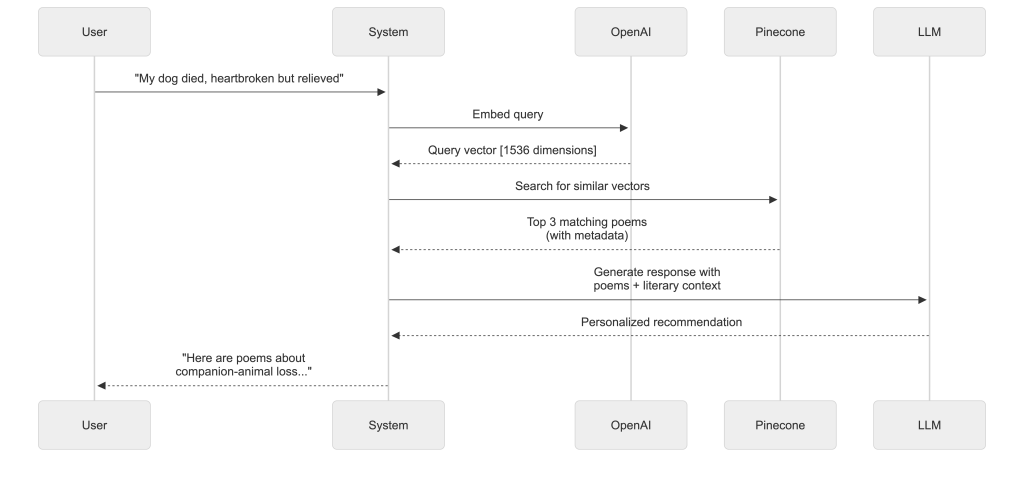
When someone searches by saying, “My dog died last week. I’m heartbroken but relieved he’s no longer suffering,” the system embeds that query and finds poems whose overall semantic representation is most similar to the query. The result is that sad yet ambivalent poems about companion-animal loss rise to the top, not poems about human death, which matters because suggesting the wrong type of grief poem can feel weird, irrelevant, or, for some people, deeply insulting.
The mood and theme tags serve a second purpose. They provide the AI literary guide with context when it explains why a particular poem might resonate with the user’s feelings.
As noted earlier, the system continues to evolve; it is a work in progress.
If you ask poetry explorer to find you poetry about losing your human best friend, you’ll notice the system returns poetry about the grief of losing your dog. This is an instance where the LLM misclassified the theme, and the humans didn’t notice. A good example of why human oversight matters. And why analysis, revision, and refinement are an ongoing process. It isn’t something you can do once and forget.
LLMs are excellent at the grunt work of initial classification, but poetry is subjective, messy, and nuance matters. That’s why every mood and theme assignment gets human review from us. The AI suggests; the humans decide. That’s the balance that makes this work.
Reading Material
These aren’t citations. They are papers worth reading if this work interests you.
- Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks (Nils Reimers, Iryna Gurevych)
- Dense Passage Retrieval for Open-Domain Question Answering (Vladimir Karpukhin et al.)
- A computational analysis of poetic style: Imagism and its influence on modern professional and amateur poetry (Justine T. Kao, Dan Jurafsky)
- Decoding Emotion in Ancient Poetry: Leveraging Generative Models for Classical Chinese Sentiment Analysis (Quanqi Du et al.)
- Emotion Analysis in NLP: Trends, Gaps and Roadmap for Future Directions (Flor Miriam Plaza-del-Arco et al.)
- A Review of Human Emotion Synthesis Based on Generative Technology (Fei Ma et al.)
- Interpretable Text Embeddings and Text Similarity Explanation: A Survey (Juri Opitz et al.)
- Understanding poetry using natural language processing tools: a survey (Mirella De Sisto et al.)
- Applications of NLP in Computational Poetics and Literary Analysis (Dave Paulson, Simeon Leonard)
